
MySQL复制的优点主要包括以下3方面:
{ 如果主服务器出现问题,可以快速切换到从服务器提供服务;
{ 可以在从服务器上执行查询操作,降低主服务器的访问压力;
{ 可以在从服务器上执行备份,以避免备份期间影响主服务器的服务。
由于MySQL实现的是的复制,所以主从服务器之间存在一定的差距,在从服务器上进行的查询操作需要考虑到这些数据的差异,一般只有更新不频繁的数据或者对实时性要求不高的数据可以通过从服务器查询,实时性要求高的数据仍然需要从主数据库获得。
安装配置
(1) 确保主从服务器上安装了相同版本的数据库。因为复制的功能在持续的改进中,所以在可能的情况下推荐安装最新的稳定版本。
(2) 在主服务器上,设置一个复制使用的账户,并授予REPLICATION SLAVE权限。这里创建一个复制用户hollowJ,可以与192.168.0.204:3307(从库)的主机进行连接。
grant replication slave on *.* to hollowJ@'192.168.0.204' identified by 'hollow';
注意,mysql有的命令必须在本地执行,比方说上面这个,否则即使使用root,也会提示
Access denied for user 'root'@'%' (using password: YES)
(3) 修改主数据库服务器的配置文件,my.cnf中[mysqld]段开启BINLOG,并设置service-id的值。
# For advice on how to change settings please see# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html# *** DO NOT EDIT THIS FILE. It's a template which will be copied to the# *** default location during install, and will be replaced if you# *** upgrade to a newer version of MySQL.[mysqld]# Remove leading # and set to the amount of RAM for the most important data# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.# innodb_buffer_pool_size = 128M# Remove leading # to turn on a very important data integrity option: logging# changes to the binary log between backups.log-bin=mysql-bin //这里开启后,mysql的所有操作日志都会记录并同步到从属节点上# These are commonly set, remove the # and set as required.# basedir = .....# datadir = .....# port = ..... server_id =3306 //每个实例的唯一标示,可用ip,这里使用ip# socket = .....# Remove leading # to set options mainly useful for reporting servers.# The server defaults are faster for transactions and fast SELECTs.# Adjust sizes as needed, experiment to find the optimal values.# join_buffer_size = 128M# sort_buffer_size = 2M# read_rnd_buffer_size = 2M sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
改完配置,请重启主服务器!!否则下面的结果将无法看到。
mysql>show master status;
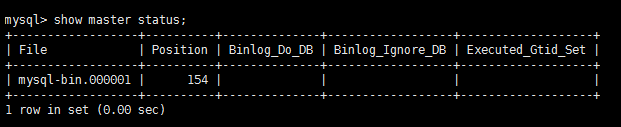 上面我们就得到了主服务器上当前的二进制日志名和偏移量值。这个操作的目的是为了在从数据库启动以后,从这个点开始进行数据恢复。
上面我们就得到了主服务器上当前的二进制日志名和偏移量值。这个操作的目的是为了在从数据库启动以后,从这个点开始进行数据恢复。
(4) 修改从数据库的配置文件my.cnf,增加servier-id参数。注意service-id的值必须是唯一的,不能和主数据库的配置相同,如果有多个从数据库服务器,每个从数据库服务器必须有自己唯一的server-id。
(5) 对从数据库服务器做相应设置,指定复制使用的用户,主数据库服务器的IP、端口、以及开始执行复制的日志文件和位置等。
关键的来了,前面的操作都是为这一部做准备。在从节点执行下面命令:
mysql> change master to master_host='192.168.0.204',master_port=3306,master_user='hollowJ',master_password='hollow',master_log_file='mysql-bin.000001',master_log_pos=154;Query OK, 0 rows affected, 2 warnings (0.14 sec)mysql> start slave;Query OK, 0 rows affected (0.06 sec)
在从服务器上,启动slave线程
(12) 这时slave上执行show slave status\G; 命令:
mysql> show slave status\G;*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.0.204 Master_User: hollowJ Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 154 Relay_Log_File: localhost-relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes
这表明slave已经连接上master,等待主库的发送事件。
快去主库创建个表,插些数据,看看丛库是否能够同步到。^_^
主要复制启动选项
log-slave-updates
这个参数用来配置从服务器上的更新操作是否写二进制日志,默认是不打开的。但是如果这个从服务器同时也要作为其他服务器的主服务器搭建一个链式的复制,那么就需要打开这个选项,这样它的从服务器将获得它的二进制日志以进行同步操作。
这个启动参数要和--logs-bin参数一起使用。
master-connect-retry
用来设置在主服务器的连接丢失的时候重试的时间间隔,默认是60秒。
read-only
设置从服务只能接受超级用户的更新操作,从而限制应用程序错误的对从服务器的更新操作。
在主服务器上设置一个帐号,并使用此账号在从服务器上登录。
主:
mysql> grant all privileges on *.* to bai@'%' identified by '123456';
从:
使用read-only启动从mysql
如果不关闭主服务器,从服务重新启动后无需重新设置从服务与主服务器的主从关系。
指定复制的数据库或者表
可以使用replicate-do-db、replicate-do-table、replicate-ignore-db、replicate-ignore-table或replicate-wild-do-table来指定从主数据库复制到从数据库的数据库或者表。有些时候用户只需要将关键表备份到从服务器上,或者只需要将提供查询操作的表复制到从服务器上,这样就可以通过配置这几个参数来筛选进行同步的数据库和表。
replicate-do-table的演示:
首先在主数据库的test数据库中创建两个表repl_test和repl_test1然后从数据库启动的时候指定replicate-do-table=test.repl_test,即只复制repl_test表。最后主数据库更新两张表,并检查数据复制情况。
(1) 首先检查主从数据库上的两个表的记录,主从数据库是相同的
(2) 然后关闭从服务器,,然后重新启动时指定复制其中一个表。
(3) 更新主数据库上test.repl_test和test.repl_test1两张表,并检查从服务器。
slave-skip-errors
在复制过程中,由于各种原因,从服务器可能会遇到执行BINGLOG中的SQL出错的情况(比如主键冲突),在默认情况下,从服务器将会停止复制进程,不再进行同步,等等用户介入处理。这种问题如果不能及时发现,将会对应用或者备份产生影响。此参数的作用就是用来定义复制过程中从服务器可以自动路过的错误号,这样复制过程中遇到定义中的错误号时,便可以自动路过,直接执行后面的SQL语句,以此来最大限度地减少人工干预。此参数可以定义多个错误号,或者通过定义成all路过全部的错误。具体语法如下:
--slave-skip-errors=[err_code1,err_code2,…|all]
如果从数据库主要是作为主数据库的备份,那么就不应该使用这个启动参数,设置不当,很可能造成主从数据库的数据不同步。但是,如果从数据库仅仅是为了分担主数据库的查询压力,且对数据的完整性要求不是很严格,那么这个选项的克可以减轻数据库管理员维护从数据库的工作量。
日常管理维护
复制环境配置完成后,数据库管理员需要经常进行一些日常监控和管理维护工作,以便能及时发现一些复制中的问题,并尽快解决,以此来保持复制能够正常工作。
查看从服务器状态。
为了防止复制过程中出现故意从而导致复制进程停止,我们需要经常检查从服务器的复制状态。一般用show slave status\G命令检查。
在显示的这此信息中,我们主要关心“Slave_IO_Running”和“Slave_SQL_Running”
{ Slave_IO_Running:此进程负责slave从master上读取BINGLOG日志,并写入slave上的中继日志中。
{ Slave_SQL_Running:此进程负责读取并且执行中继日志中的BINLOG日志。
只要其中有一个进程状态是NO,则表示复制进程停止,错误原因可以从“Last_Errno”字段 的值中看到。
除了查看上面的信息。用户还可能了解到从服务器的配置情况以及当前和当服务器的同步情况。
主从服务器同步维护
在某些繁忙的OLTP(在线事务处理)系统上,由于主服务器更新频繁,而从服务器由于各种原因(比如硬件性能较差)导致更新速度较慢,从而使得主从服务器之间的数据差距起来起大,最终对某些应用产生影响。在这种情况下,我们就需要定期地进行主从服务器的数据同步,使得从数据差距能够减到最小。常用的方法是:在负载较低的时候暂时阻塞主数据库的更新,强制主从数据库的更新同步。具体步骤如下
(1) 在主服务器上,执行以下语句(注意,会主数据库的所有更新操作):
记录SHOW语句输出的日志名和偏移量,这此是从服务器复制的目的坐标。
(2) 在从服务器上执行下面语句,其中MASTER_POS_WAIT()函数的参数是前面步骤中得到的复制坐标值:
这个select语句会阻塞直到从服务器达到指定的日志文件和偏移后,返回0,如果返回-1,则表示超时退出。查询返回0时,则从服务器与主服务器同步。
(3) 主服务器上,解锁表
UNLOCK TABLES;
从服务器复制出错的处理
首先需要确定是否是从服务器的表与主服务器的不同造成的。如果是表结构不同导致,则修改从服务器的表与主服务器的相同,然后重新运行START SLAVE语句。
如果不是表结构不同导致的更新失败,则需要确认手动更新是否安全,然后忽视来自主服务器的更新失败的语句。路过来自主服务器的语句的命令为
SET GLOBAL SQL_SLAVE_SKIP_SOUNTER=n
其中n的取值为1或2。如果来自主服务器的更新语句不使用AUTO_INCREMENT或者LAST_INSERT_ID(),n值应为1,否则为2。原因是使用AUTO_INCREMENT或者LAST_INSERT_ID()的语句需要从二进制日志中取两个事件。
以下例子就是在从服务器端模拟路过主服务器的两个更新语句的效果。
(1) 首先,在从服务器端先停止复制进程,并设置路过两个语句:
(2) 然后在主服务器插入三条记录。
(3) 从服务器端启动复制进程,检查测试的表一,发现插入的两条记录被跳过了,只执行了第3条插入语句:
log event entry exceeded max_allowed_packet的处理
如果应用中使用大的BLOG列或者长字符串,那么在从服务器上恢复的时候,可能会出现:log event entry exceeded max_allowed_packet的错误,这是因为含有大文本的记录无法通过网络进行传输导致。解决的办法就是在主从服务器上增加max_allowed_packet参数的大小,这个参数默认值为1MB,可以按照实际需要进行修改,比如下例中将其增大为16M:
同时在my.cnf里,设置max_allowed_packet=16M,保证下次数据库重新启动后参数继续有效。
多主复制时的自增长变量冲突问题
在多台主服务器对一台从服务器时,如果主服务器的表采用自动增长变量,那么复制到从服务器的同一张表后很可能会引起主键冲突,同为系统参数auto_incerment_incerment和auto_incerment_offset默认值为1,这样多台主服务器的自增变量列迟早会发生冲突。在单主复制时,可以采用默认设置,不会有主键冲突发生。但是使用多主复制时,就需要定制auto_incerment_incerment和auto_incerment_offset的设置,保证多主之间复制到从数据库不会有重复冲突。比如。两个master的情况可以按照以下设置。
{ Master1:auto_incerment_incerment=2,auto_incerment_offset=1;(1,3,5,7序列)
{ Master2:auto_incerment_incerment=2,auto_incerment_offset=0;(2,4,6,8序列)
首先在参数是默认值的时候往表中插入记录:
然后把auto_incerment_incerment的值改成10再插入记录:
从测试的结果上看,新插入的记录不再连续了,每次增加10。接着再修改auto_increment_offset参数:
从插入记录的结果上可以了解,auto_increment_offset参数设置的是每次增加后的偏移量,也就是每次按照10累加之后,还需要增加5个偏移量。
通过这两个参数可以方便地设置不同的主服务器上的自动增长列的值的范围,这样在这此数据复制到从服务器上时可以有交地避免主键的重复。
查看从服务器的复制进度
很多情况下,我们想要知道从服务器复制的进度如何。知道了这个差距,可以帮助我们判断是否需要手工来做主从的同步工作,也可以帮助我们判断从服务器上做统计的数据精度如何。这个值可以通过SHOW PROCESSLIST列表中的Slave_SQL_Running线程的Time的值行到,它记录了从服务器当前执行的SQL时间戳与系统时间之间的差距,单位是秒。
(1) 首先在主服务器上插入一个包含当前时间戳的记录:
(2) 为了方便模拟时间,这里把从服务器上复制的IO进程集下来,使得从服务器暂时不写中继日志,也就是最后执行的SQL就是当前中继日志中最后一个SQL。
(3) 一段时间之后,再从服务器端查询复制的情况:
(4) 这时再查询SQL线程的时间,显示的Time值,单位是秒。这说明是多少秒之间的更新。
由于MySQL复制的机制是执行主服务器传输过来的二进制日志,二进制日志中的每个语句通过设置时间戳来保证执行时间和顺序的正确性,所以每个语句执行之前都会首先设置时间戳,而通过查询这个进程的Time就可以知道最后设置的时间戳和当前时间的差距。
切换主从服务器
(1) 首先要确保所有的从数据库都已经执行了relay log中的全部更新,在每个从服务器上执行STOP SLAVE IO_THERAD,然后检查SHOW PROCESSLIST的输出,直到盾到状态是Has read all relay log,表示更新都很执行完毕。
(2) 在从S1数据库上,执行STOP SLAVE停止从服务,然后RESET MASTER重置成主数据库。
(3) 在S2上,停止从服务。然后更换主数据库设置,然后再开启复制(需要重新设置用户以及二进制日志文件?)
(4) 通知所有的客户端将应用指向S1服务器。
(5) 删除新的主数据库服务器上的master.info和relay-log.info文件,否则下次重启的时候还会按照从服务器启动。
(6) 最后,如果M服务器可以修复,则可以按照S2的方法配置成S1的从服务器。
上面测试的步骤是默认S1是打开的log-bin选项的,这样重置成数据库后可以将二进制日志传输到期货从服务器上。其次,S1上没有打开log-slave-updates参数,否则重置成主数据库后,可能会将已经执行过的二进制日志重复传输给S2,导致S2的同步错误。